January 27, 2025
DeepSeek(ディープシーク)ショック テック株に影響

DeepSeek(ディープシーク)ショック テック株に影響
中国発AI「DeepSeek(ディープシーク)」が世界のAI開発競争を揺るがす!わずか2か月、約560万ドルで最先端モデルを実現し、NVIDIA株価やマグニフィセント7にも影響。DeepSeekショックによるAI市場への影響をわかりやすく解説します。
Woodstockアプリなら米国マーケットの情報交換が気軽に行えます。今なら最大2万円分が当たるキャンペーン実施中👇画像をタップしてチェック!
- DeepSeekとは—「わずかなリソースで最先端モデル」を実現
- 度肝を抜いたDeepSeek-R1の凄さ
- OpenAI-o1と肩を並べる推論力
- コーディングタスクにも強い
- 小型モデル(Distill版)も充実
- どうしてここまで強いのか?
- 要するに…
- 開発に不利な環境にも関わらず
- 米国の規制が「逆に効率化を促した」
- DeepSeek開発者はどんな人物なのか
- DJI創業者からのオファーも
- 「好奇心のままに研究を進める」組織文化
- DeepSeekこそ”OpenAI”?—オープンソースで公開
- GPU高性能主義に疑問が...
- 株式市場にも影響が及ぶ
- NVIDIAへの影響
- マグニフィセント7への影響
- ソフトバンクG 約8.3%下落
- 中国の規制はどうなる?
- 今後の行方と注目点
- 推論(Reasoning)能力の競争
- 大規模投資モデルの採算性
- GPUサプライチェーンへの再評価
- 中国のAI競争力の再評価
- まとめ
- 投資の始めの一歩はウッドストックで

2024年以降、ChatGPTをはじめとする大規模言語モデル(LLM)の話題が尽きることはありません。OpenAIのGPTシリーズ、Meta(旧Facebook)のLlama、AnthropicのClaudeなど、米国のスタートアップ・ビッグテックが激しい開発競争を繰り広げる中、突如注目を浴びたのが中国の「DeepSeek(ディープシーク)」です。
今回のWeekly Bites!では、米国投資アプリを運営するWoodstock経済部が、
- DeepSeek(ディープシーク)って何?
- 何がすごいの?
- 株価にどんな影響があるの?
といった疑問を持った方に向けてわかりやすく解説します。
- DeepSeekとは—「わずかなリソースで最先端モデル」を実現
- 度肝を抜いたDeepSeek-R1の凄さ
- OpenAI-o1と肩を並べる推論力
- コーディングタスクにも強い
- 小型モデル(Distill版)も充実
- どうしてここまで強いのか?
- 要するに…
- 開発に不利な環境にも関わらず
- 米国の規制が「逆に効率化を促した」
- DeepSeek開発者はどんな人物なのか
- DJI創業者からのオファーも
- 「好奇心のままに研究を進める」組織文化
- DeepSeekこそ”OpenAI”?—オープンソースで公開
- GPU高性能主義に疑問が...
- 株式市場にも影響が及ぶ
- NVIDIAへの影響
- マグニフィセント7への影響
- ソフトバンクG 約8.3%下落
- 中国の規制はどうなる?
- 今後の行方と注目点
- 推論(Reasoning)能力の競争
- 大規模投資モデルの採算性
- GPUサプライチェーンへの再評価
- 中国のAI競争力の再評価
- まとめ
- 投資の始めの一歩はウッドストックで
「たった2か月、約560万ドル(約8億8,300万)で、GoogleやOpenAIに追いつく──」。この数字は、多くのAI研究者と投資家の度肝を抜きました。というのも、OpenAIは年間50億ドル(約7,700億)、Googleは2024年に500億ドル(約7.7兆円)超の資本的支出(CapEx)を見込むとされ、マイクロソフトがOpenAIに投じた額は130億ドル(約2兆円)以上。そんな“巨額AI開発競争”の構図を中国のDeepSeekが大きく揺るがしています。
株価にも影響があり、DeepSeekの最新モデル発表を受け、市場が反応しNasdaq100先物が200ポイント超下落と話題になっています。
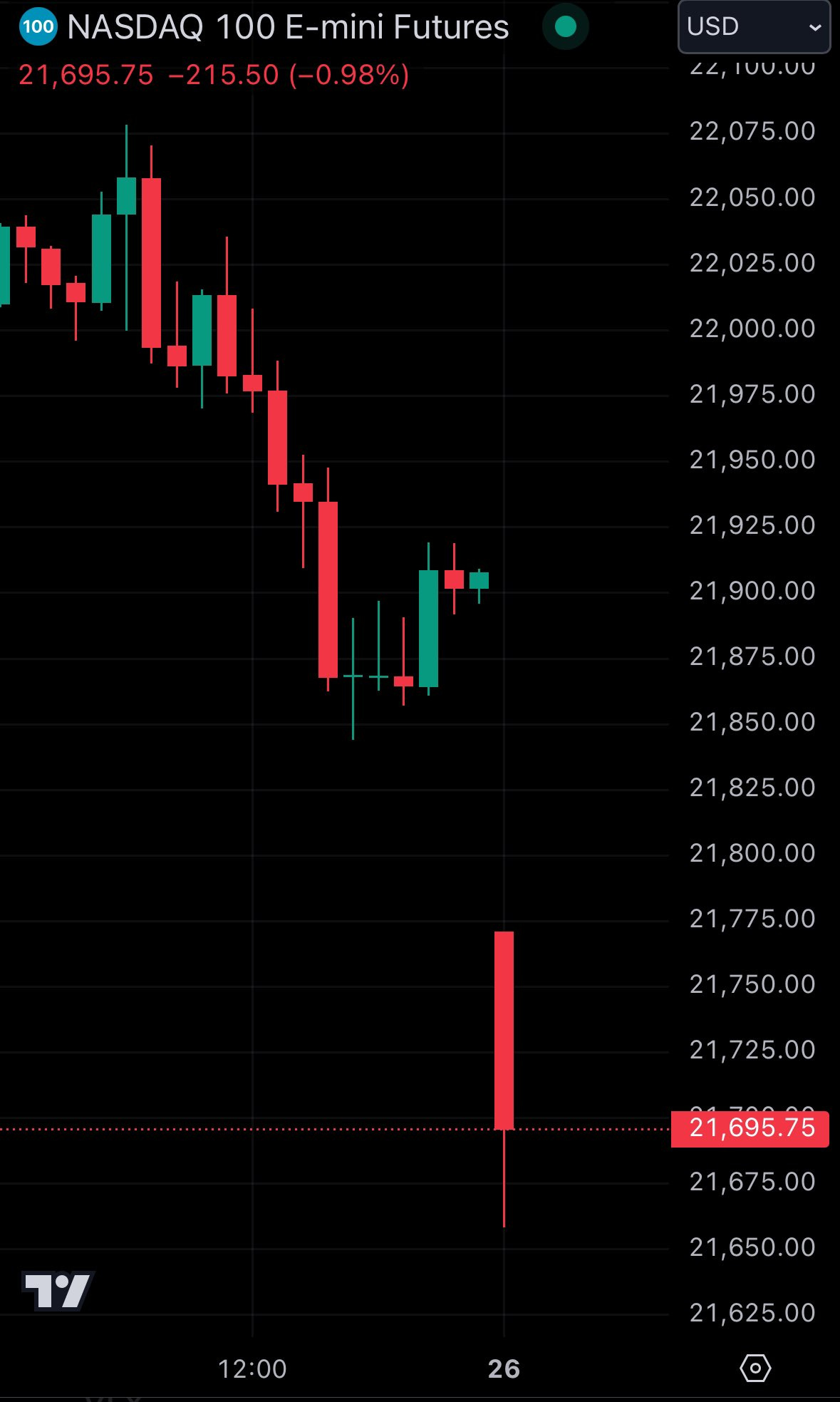
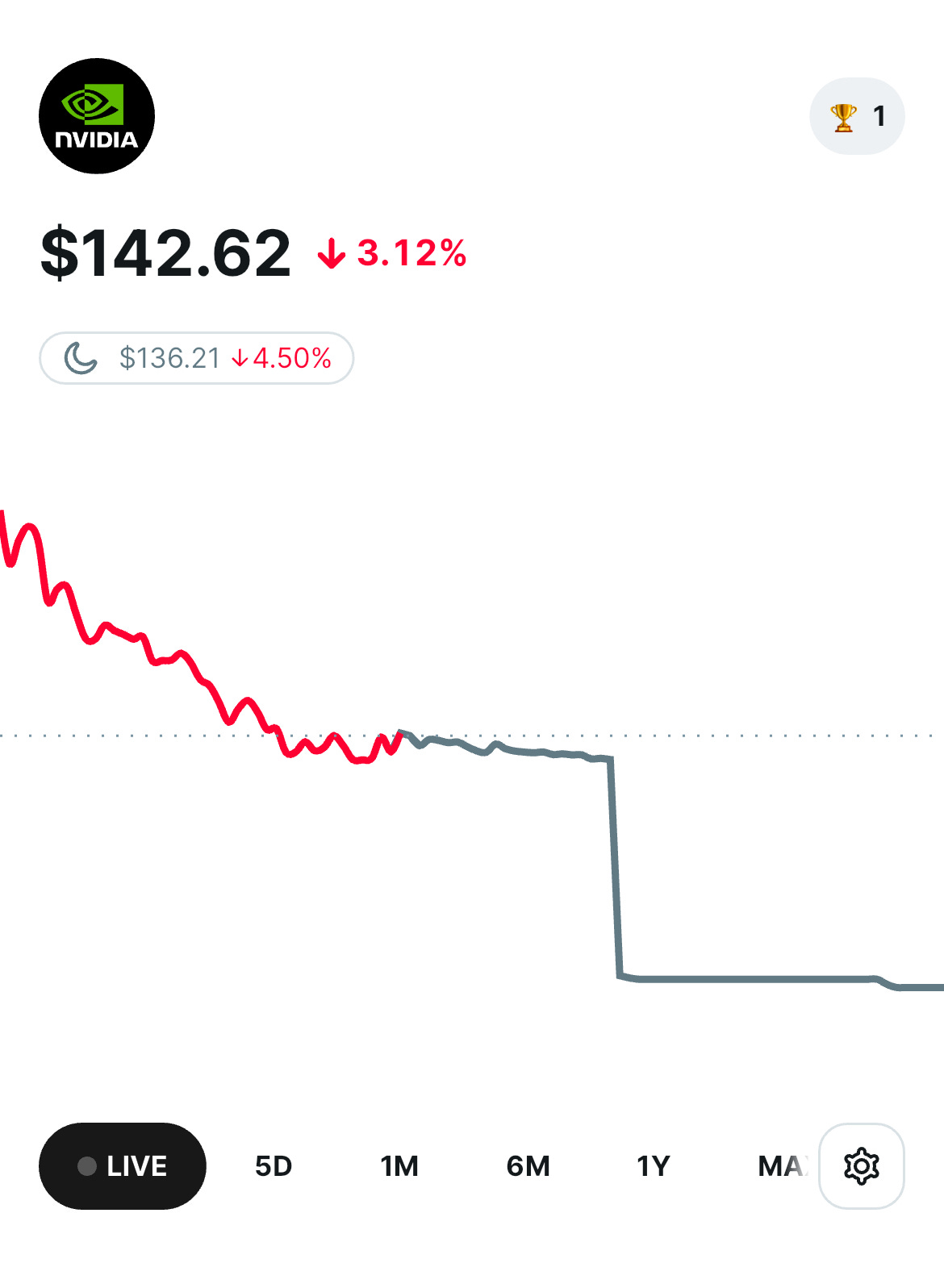
NVIDIAもDeepSeekの発表を受け、下落したと見られます。
DeepSeekとは—「わずかなリソースで最先端モデル」を実現
DeepSeekは、中国のAIスタートアップで、大規模言語モデル(LLM)を開発している企業です。ChatGPTやClaudeのような、AIモデルを発表し、高性能なAI技術でこれまで注目を集めてきました。
DeepSeekは先日最新版の「DeepSeek-R1」を発表。その性能の高さに度肝を抜かれました。では、「DeepSeek-R1」の何がすごいのか、公式ドキュメントを元に、一緒に見ていきましょう。
度肝を抜いたDeepSeek-R1の凄さ
OpenAI-o1と肩を並べる推論力
大規模言語モデルの実力を測る指標として、数学や推論系のベンチマークが注目されます。たとえばDeepSeek-R1の場合、以下の結果が報告されています(ソース:DeepSeek公式ドキュメント)。
- AIME 2024 (Pass@1):79.8%
→ これはアメリカの数学コンテスト問題(AIME)に対して、1回目の回答で正解する確率を示しています。OpenAI-o1-1217とほぼ同等の水準です。 - MATH-500 (Pass@1):97.3%
→ 数学系の難問500問を解くテストで、DeepSeek-R1はOpenAI-o1を上回る正答率を叩き出しています。
コーディングタスクにも強い
DeepSeek-R1はコード生成やバグ修正といったプログラミング系タスクでも高い実績を持ちます。
- LiveCodeBench (Pass@1-CoT):65.9%
→ 1回目の提出での正答率がOpenAI-o1-1217を上回るとされ、非常に優秀です。 - Codeforces (Elo Rating):2029
→ オンラインプログラミング競技サイトの擬似レーティングでは、OpenAI-o1-1217とほぼ同レベルという評価が出ています。
小型モデル(Distill版)も充実
さらに「DeepSeek-R1-Distillモデル」では、1.5B~70Bといったパラメータ数の異なるモデルを複数用意。大きなGPUを使わなくても高い推論能力を実現でき、OpenAI-o1-miniを上回る性能を示すバージョンもあると報告されています。
どうしてここまで強いのか?
- 大規模強化学習(RL)を直接適用
従来の教師あり学習(SFT)に比べ、AI自ら試行錯誤しながら「思考プロセス」を洗練させる手法を採用。これが数学や論理問題、コーディングなどの“深い考察”が必要なタスクに強い理由です。 - 蒸留技術で“小型”も実用レベル
大きなモデルだけでなく、Distill(知識蒸留)によって軽量モデルにノウハウを移行。パラメータ数が少なくても驚くほど高い性能を示すため、リソースが限られた環境でも応用可能です。 - オープンソース & 低コスト
MITライセンスで公開され、商用利用も含めて自由度が高いのが魅力。APIやWebUIの料金も比較的リーズナブルに設定されており、試しやすい点も評価されています。
要するに…
- DeepSeek-R1は、数学・推論・プログラミングといった高度なタスクでOpenAI-o1シリーズと同等以上の成績を叩き出す“考えるAI”。
- 蒸留版(Distillモデル)により、小規模リソース下でも高精度を実現。
- オープンソースで低コスト、誰でも試しやすい環境が整っている。
こうした要素が重なり合った結果、「度肝を抜かれるレベルの性能と使いやすさ」が世界中から注目されているのです。
開発に不利な環境にも関わらず
R1のベースとなっているDeepSeekが発表したモデル「DeepSeek Version 3(V3)」も、アメリカ側のGPT-4やClaudeシリーズ、MetaのLlamaなどを一部分野で上回る性能を示したといいます。中でも注目されるのは、「数学問題やコードバグ修正などの専門的タスク」で非常に高い正答率を叩き出したことです。
さらにその衝撃を加速させたのは、「コストの異常な低さ」です。年間50億~100億ドル(7,700億~7.7兆円)単位で開発を続ける米国勢に対し、DeepSeekはたった約560万ドル(約8億8,300万)。
しかも使用したGPUは、米国の輸出規制で性能を抑えられたNVIDIAの「H-800」。従来なら「中国の最先端AI開発には不利」と思われていた制限下で、この飛躍を可能にしたのです。
米国の規制が「逆に効率化を促した」
米中のテクノロジー競争に詳しい専門家は、DeepSeekが軽量GPU環境で高性能を出す過程で「MoE(Mixture of Experts)アーキテクチャ」や「FP8(8ビット浮動小数点)訓練」などを高度に使いこなし、効率的なチューニング手法を追求した結果だと指摘します。
CNBCのインタビューで登場したPerplexity社の共同創業者でCEOのアルヴィンド・スリニヴァス氏は、次のように述べています:
“Because they had to figure out workarounds, they actually ended up building something a lot more efficient. Necessity is the mother of invention.”
(訳)「規制による制限をどうにか回避しようとする中で、結果的に非常に効率的なシステムを構築してしまったのです。『必要は発明の母』とはまさにこのことです。」
GPUの性能が抑えられたからこそ、新しい訓練手法やアーキテクチャ上の工夫が生まれ、予想外の速さでOpenAIやMetaに迫るモデルを完成させてしまったというのです。スリニヴァス氏はまた、DeepSeekの技術的レポートを読んだ際の衝撃を次のように語っています。
“My surprise was that when I actually went through the technical paper, the amount of clever solutions they came up with… They cleverly figured out which has to be in higher precision, which has to be in lower precision. … They did it with so little money and such an amazing model.”
(訳)「論文を細かく読んでみると、その巧妙な解法の数々に驚かされました。どこを高精度にし、どこを低精度にするかをきわめて上手く見極めている。… これほど少ない予算で、あれほど優れたモデルを作ったのは驚異的です。」
DeepSeek開発者はどんな人物なのか
DeepSeekの創業・開発者はリャン・ウェンフェン(梁文峰)氏です。リャン氏は、中国・浙江(せっこう)大学でAIを専攻していた頃から「AIは必ず世界を変える」という信念を抱き続けた人物です。
2008年前後、中国ではまだAIが大きく注目されていなかった時期に、周囲が大企業の開発職へ就く中、彼だけは成都の安価なアパートで試行錯誤を重ねました。その後、あらゆるビジネス領域へのAI応用を模索するうちに金融に可能性を見出し、2015年にクオンツ(量的)ファンド「高翔量化(High-Flyer Quant)」を設立。わずかな年数で運用資産額1000億元(約2兆円規模)にまで育て上げました。
DJI創業者からのオファーも
面白いエピソードとして、リャン・ウェンフェン氏は若い頃に友人から『深センの城中村(じょうちゅうそん)で「飛行機械(ドローン)」の開発チームに入らないか』と誘いを受けたといいます。
しかし当時から「AIで世界を変えたい」という強い信念を持っていたリャン氏は、この誘いを断り、自分の道を歩むことを選んだとインタビュー記事で言及されています。
“Fun fact: In the early years, he had a similarly crazy friend who tried to get him to join his team for making flying machines in a Shenzhen [urban village], an endeavor considered ‘nonsense’ [不靠谱]. Later, this friend founded a $100 million company called DJI.”
(出典:Cosmia_Nebula訳インタビュー「The Madness of High-Flyer: The Approach to LLM by an AI Giant that Few See」より)
中国でドローンって...そうです、DJIです。
その友人———フランク・ワン氏は、後に世界的ドローン企業として知られる「DJI」を創業。結果的にDJIは大成功を収めることになりましたが、リャン氏は自身の“AIへのこだわり”を貫き通し、のちにクオンツファンドのHigh-Flyerを立ち上げることになります。
「好奇心のままに研究を進める」組織文化
クオンツファンドHigh-Flyerは研究開発予算を潤沢に投じ、2021年には1万枚以上のNVIDIA A100を搭載したスーパーコンピュータ「Firefly II」を構築。2023年、このAI研究部門を独立させて「DeepSeek(深度求索)」を設立し、大規模言語モデル(LLM)や汎用人工知能(AGI)の研究に本格的に着手しました。
リャン氏は社内文化として「経験よりも好奇心・探究心」「KPIを細かく設定しない自由さ」を重視し、インタビューでは次のように語っています。
“If we look at the long term, experience is not so important. Basic ability, creativity, and love are more important.”
(訳)「長い目で見れば、経験はそれほど重要ではありません。むしろ、基礎的な能力、創造性、そして“愛”こそがより大切なのです。」
こうした価値観が、短期間・低コストでの高性能モデル開発や、オープンソースへの積極姿勢といった結果に結びついたのかもしれません。
DeepSeekこそ”OpenAI”?—オープンソースで公開
DeepSeekが驚きを与えたのは、「モデルをオープンソースで無償公開」した点です。ウェイト情報(モデルパラメータ)までも公開されているため、誰でも利用・改変が可能。膨大なGPU資源や巨額の資金を持たない中小企業や個人開発者でも、これを基盤にサービスを開発できるのです。
インタビューやレポートでも繰り返し強調されているのが、「一度オープンソースが追いつけば、世界中の開発者がそのモデルをベースに開発する」という事実です。スリニヴァス氏はこう言及しています:
“It's known that once open-source is caught up or improved over closed source software, all developers migrate to that.”
(訳)「一度オープンソースがクローズドソースに追いついたり上回ったりすれば、開発者はみなオープンソースに移行するのが通例です。」
OpenAIのCEO、サム・アルトマン氏は、自身のSNSで「コピーすること自体は容易だが、新しいリスクを取って未知のものに挑むのは難しい」という趣旨のコメントを残し、暗にDeepSeekを批判するような投稿を行いました。

OpenAIサムアルトマン本人Xより
しかし、その「コピー」という言い分に対しては、「GoogleもTransformer(変換器)を最初に考案したが、OpenAIはそれを利用して商品化しただけ」といった指摘もあり、AI業界では「そもそも皆が皆、先人の技術を参照・改良し合っている」という認識が広がりつつあります。
GPU高性能主義に疑問が...
これまでAI分野では、「とにかく最高性能のGPUを大量に使う」ことが性能アップへの近道と考えられていました。特にNVIDIAのH100は争奪戦の的となり、MicrosoftやGoogle、Metaが数十億ドルをかけて調達していると言われています。しかし、DeepSeekの事例は、「一段下のGPUでも工夫すれば最先端モデルに匹敵する性能が得られる」可能性を示したのです。
そのため、GPUメーカー各社のビジネス戦略にも影響が生じるでしょう。ハイエンドGPUだけでなく、中位レンジ(あるいは旧世代)のGPUを使った省エネかつ効率的なAI開発ニーズが高まるかもしれません。さらに、FPGAやASICなど、GPU以外の演算ハードウェアの需要も拡大する可能性があります。
一方で、NVIDIAを筆頭とする米国メーカーが持つ“ハードウェア的アドバンテージ”は依然として強力です。DeepSeekが使用したH-800は、あくまでH100を性能ダウンさせた輸出規制対応版であるとはいえ、NVIDIA製品そのものには変わりありません。今後は米国の規制強化や中国の独自GPU開発などがどう影響するか、予断を許さない状況といえます。
株式市場にも影響が及ぶ
NVIDIAへの影響
米国の半導体大手NVIDIAは、大規模言語モデル(LLM)ブームのいわば“要”として、2024年後半から2025年にかけて急成長を遂げ、株価も過去最高水準を記録しました。
IBD(Investor's Business Daily)によると、「GPUの需要が頭打ちになるのでは」という懸念が広がり、先週末には先物取引でNVIDIA株が下落に振れ、Robinhoodなどの取引プラットフォームでも売り圧力がかかったケースが報告されました。
さらに、NVIDIAが2月26日に予定している決算では、GPUの中国向け売上や次世代Blackwell(H200)チップの開発計画、そして米国政府の輸出規制強化への対応策が注目されています。
もしDeepSeekをはじめとする中国AI企業が、制限のあるチップで十分な成果を上げ続けると、市場ではNVIDIAの長期的な伸びに疑問符を付ける投資家が増えるかもしれません。ただし、NVIDIAが持つソフトウェアスタックやエコシステムの強みは依然として大きく、調整局面が「押し目買い」のチャンスになると考える向きもあるため、株価が大幅に崩れるかどうかは今後の決算内容や米中関係によって左右されそうです。
マグニフィセント7への影響
NVIDIAを含む“マグニフィセント7”と呼ばれる米国主要ハイテク企業群(Microsoft、Apple、Amazon、Alphabet、Meta、Tesla)は、AIやクラウド事業で莫大な開発費を投入してきました。特にOpenAIへ出資しているMicrosoftや、自社でLLMを展開しているGoogle(Alphabet)、そしてMetaのLlama開発などは、膨大なGPUリソースを背景にモデルを強化してきたことで知られています。ところが、今回のようにDeepSeekの登場によって「必ずしも大規模な予算と高性能GPUの独占が必要ではない」という認識が広がれば、こうした“大型投資”の妥当性が疑問視される局面が出てきました。
経済学者のエド・ヤーデニ氏は、「莫大な資本支出が先行している一方で、成果(売上・利益)が追いつかず、今後の決算で失望売りを招くリスクがある」と指摘しています。これを受け、マグニフィセント7の一角であるMeta、Alphabetなどでも株価が不安定となる可能性が報じられ、短期的には調整局面が避けられないかもしれません。
もっとも、Microsoftなどはソフトバンクグループらと共同で進めるAIインフラ計画に技術協力しており、新たな形で差別化を図っていく可能性があります。長期的には「さらに先端的な研究やサービスで差を付ける」というシナリオも考えられるため、マグニフィセント7株全体が一斉に下落するとは限りませんが、投資家の慎重な目線は続きそうです。
ソフトバンクG 約8.3%下落
先日、ソフトバンクグループ(SBG)はOpenAIやOracleと共同で、米国AIインフラに1000億ドル(約15兆円)を投じる「スターゲート」計画を発表しました。
今後4年をかけて投資額を5000億ドル(約78兆円)に拡大し、データセンターや研究キャンパスなどを整備するとのことです。SBGの孫正義氏はスターゲートの会長に就任し、資金調達の核となる方針が示されています。
しかし、DeepSeekが高価な最先端GPUを使わずとも大規模言語モデルを開発できることを示し、米国のAI開発競争に不透明感が強まったようです。
ソフトバンクGが莫大な資金を投じる米国AIプロジェクトの収益性や回収時期に疑問が生まれたことで投資家の慎重姿勢が高まり、本日のソフトバンク株は8.3%程度の下落に繋がったと考えられます。ソフトバンクが「AI開発にお金をかけます」と発表した直後だったため、その影響が大きく出てしまったのかもしれません。
中国の規制はどうなる?
専門家が懸念するのは、中国国内で開発されたAIモデルの「検閲リスク」です。
中国では言論の自由や政治的表現を制限する法律があり、政治的にセンシティブなトピックについては回答を回避または歪める可能性があります。もし世界中の開発者が安価かつ性能の高い“DeepSeek系モデル”を大規模に採用したとき、中国政府が定める「社会主義的価値観」への適合がどの程度染み込むか、という懸念があるのです。
CNBCのリポートでは、民主主義陣営のAI主導権をどう守るかという論点が、エリック・シュミット(元Google CEO)のコメントなどからも指摘されていました。「米国と中国、どちらの価値観が世界のAIインフラを席巻するのか」という地政学的リスクは、今後ますます議論されることになりそうです。
今後の行方と注目点
推論(Reasoning)能力の競争
ChatGPTやDeepSeek Version 3に続く次の大きなテーマは「多ステップ推論」や「思考プロセスの明示化」といった“推論特化型”モデルの開発だとされています。OpenAIは「o1」、Anthropicは「Claude Sonnet」、DeepSeekは「R1」など、それぞれが高度な推論を取り入れたモデルを相次ぎ投入。短いテキスト応答だけでなく、自律的にツールを使ったり、複雑な問題に何段階も思考を巡らせたりするAIの開発が加速しています。
大規模投資モデルの採算性
OpenAIやAnthropicなど、研究開発費を数十億ドル規模で投じる企業は、今後その投資をどこまで回収できるかが問われるでしょう。オープンソース勢による猛烈な追い上げが続くと、「AIモデル構築はマネートラップ」という投資家の懐疑論がさらに強まるかもしれません。
GPUサプライチェーンへの再評価
DeepSeekが示した「低性能GPUでもやれる」という事例を受け、Nvidia以外のプレーヤーや中位~廉価GPU製品の需要増など、多様なサプライチェーンが再編される可能性があります。これには米中間の規制・対立も大きく影を落とします。
中国のAI競争力の再評価
エリック・シュミット氏は「中国は2~3年遅れている」と言っていたが、いまや「6か月で追いついた」と語るほど急変しています。DeepSeekだけでなく、元Google中国代表の李開復(Kai-Fu Lee)氏が率いるZero One.AIなど、中国には既に国際的評価を受けるAIスタートアップが複数存在します。これから数年でさらなる台頭が予想されるでしょう。
まとめ
DeepSeekがわずか2か月、約560万ドルという限られたリソースで、OpenAIやGoogleなど米国企業の最先端モデルに肉薄する成果を示したことは、AI開発競争の前提を根本から変えつつあります。米国の輸出規制が意図した「高性能GPUの供給制限」が逆に効率化のモチベーションを生み、驚くほど小規模な投資で高性能モデルを完成させた事実は、多くの研究者や企業を刺激しています。
そして、DeepSeekが「オープンソース」という形で自社モデルを公開した結果、世界中の開発者がこれにアクセスしやすくなり、中国発モデルの存在感がさらに増す可能性があります。AIのコモディティ化が進む中、GPU産業も「ハイエンド一辺倒」ではなく、使い方やアーキテクチャ次第で大きく変動するシナリオが現実味を帯びてきたと言えるでしょう。
既存の大手企業が持つ「巨額の開発投資」は、今後もAIの最前線を切り拓くための強みとなる半面、「はるかに少ない予算で類似性能が得られる」オープンソースの趨勢がどこまで広がるかは未知数です。ビジネスとしての採算性や研究コストの正当化が、今後さらに大きな論点になるはずです。
いまや、AIの覇権をめぐる争いは単なるテックの話題に留まりません。地政学的リスクや価値観の対立、巨大投資へのリターン、そしてGPU産業の未来までも巻き込み、新たな段階へと突入しています。DeepSeekを筆頭とする中国勢の「効率への飽くなき追求」と、米国勢の「圧倒的リソースと先行知見」のぶつかり合いが、私たちの身近なサービスや産業構造をどう変えていくのか──。その動向に目が離せません。
参考:
DeepSeek. (2025, January 25). News update on DeepSeek AI. Retrieved from https://api-docs.deepseek.com/news/news250120
Bloomberg. (2025, January 27). Two interviews with the founder of DeepSeek. Bloomberg. Retrieved from https://www.bloomberg.co.jp/news/articles/2025-01-27/SQQ5B2T1UM0W00
Investor’s Business Daily. (2025, January 27). DeepSeek AI stocks, Nvidia, artificial intelligence, capital spending. Retrieved from https://www.investors.com/news/technology/deepseek-ai-stocks-nvidia-artificial-intelligence-capital-spending/
Cosmia_Nebula. (2024, November 29). Two interviews with the founder of DeepSeek. LessWrong. Retrieved from https://www.lesswrong.com/posts/kANyEjDDFWkhSKbcK/two-interviews-with-the-founder-of-deepseek
[YouTube]. (n.d.). WEBiebbeNCA?si=UIAQV4hJ2RmAwY5g. Retrieved from
投資の始めの一歩はウッドストックで
woodstock.club(ウッドストックアプリ)を活用すれば、米国市場に関する情報を集めると同時に、実際に米国株を200円からコツコツと始めることができます。
米国市場に参加している投資家たちの生の声を聞けたり、トレンドを抑えることができます。
Woodstockのタイムライン画面 / Woodstock
さらに、ウッドストックアプリではリアルタイムに他のユーザーの売買をチェックすることができます。この機能を使えば、まさしく「今、この瞬間何がトレンドなのか」が一目でわかります。
みんなの売買がリアルタイムでわかる / Woodstockアプリ
ウッドストックアプリは、以下のような特徴があります。
- 200円という少額で始めることができる。
- SNS機能でリアルタイムな意見を集められる
- 他のユーザーがどんな株を売買しているのかリアルタイムで確認できる
- 他のユーザーのポートフォリオをチェックできる
- ユーザーの半数はZ世代 などなど他にも盛りだくさん!
他のユーザーのポートフォリオを見て参考にできる / Woodstockより
弊社のwoodstock.club(ウッドストック)アプリは無料で始めることができ、口座解説もたったの2分ちょっとで完了します。
今年こそ新しいことを始めたい!と思っている方は、是非チェックしてみてください。
アプリのインストールはこちらから👇
今年こそ新しいことを始めたい!と思っている方は、是非チェックしてみてください👇